2. 数据集与流水线 (Dataset & Pipeline)
数据接入平台后,第一站就是转化为数据集 (Dataset)。数据集是整个平台内数据流转和加工的统一标准单元。
2.1 同步原始数据集
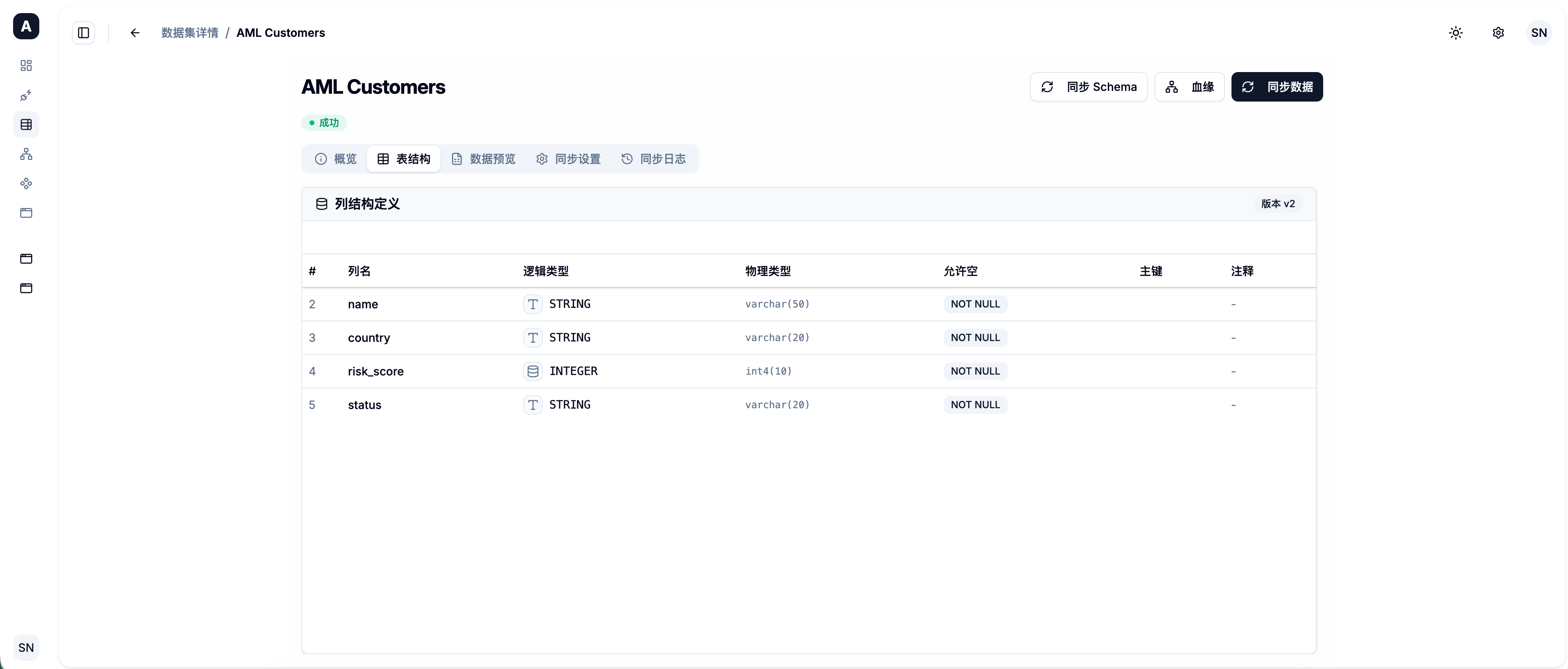
当数据源创建成功后,你需要将其中的特定表同步到平台中,这被称为原始数据集 (Raw Dataset)。
- 进入某个数据源的详情页。
- 平台会自动抓取该库下的所有表名 (Table / View)。
- 选择你需要接入的表,点击 [同步为数据集]。
- 平台会读取该表的元数据结构(列名、数据类型),并将其映射为平台的标准 Schema 类型(如
STRING,INTEGER,TIMESTAMP)。
Schema 与数据预览
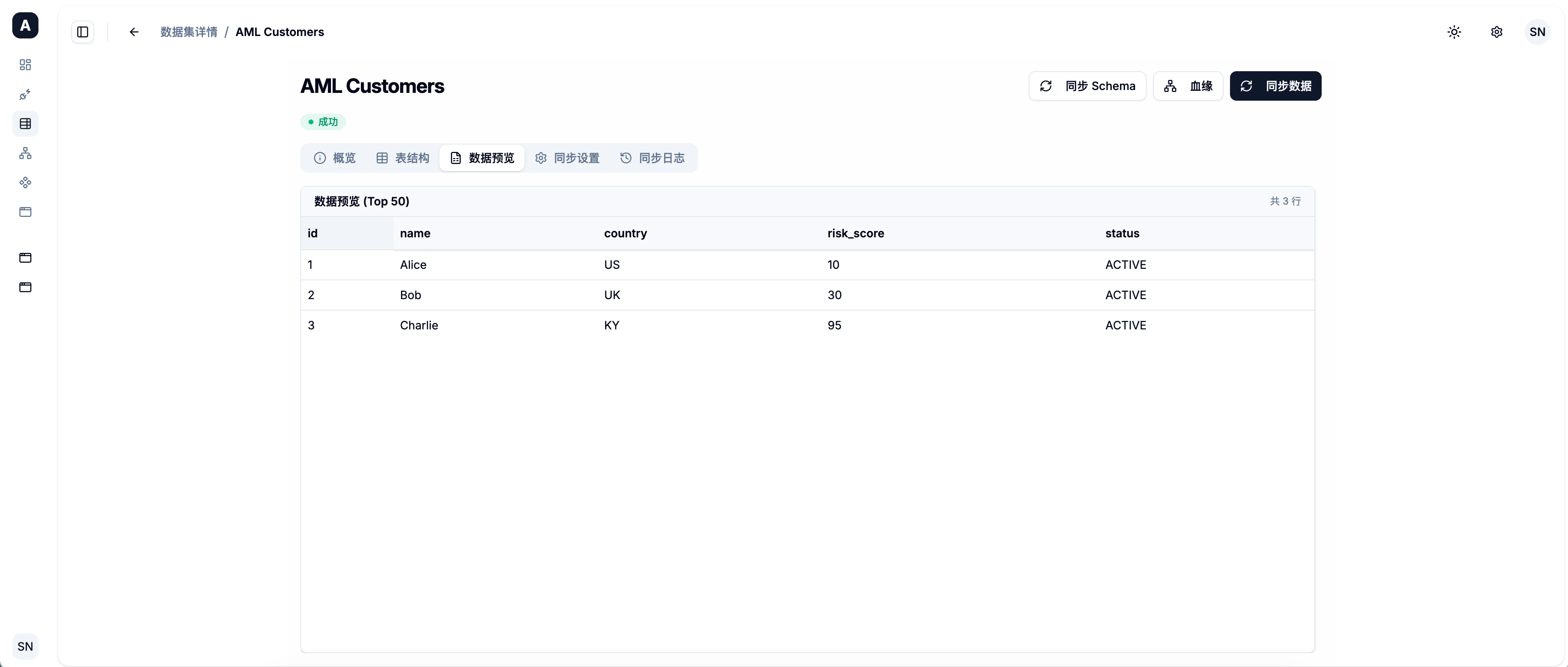
平台会自动解析表的 Schema 定义。在数据集详情页,你可以点击 [预览数据],平台会实时向底层物理库发起一个 LIMIT 50 的查询,帮助你确认数据接入是否正常。
2.2 构建派生流水线 (Pipeline)
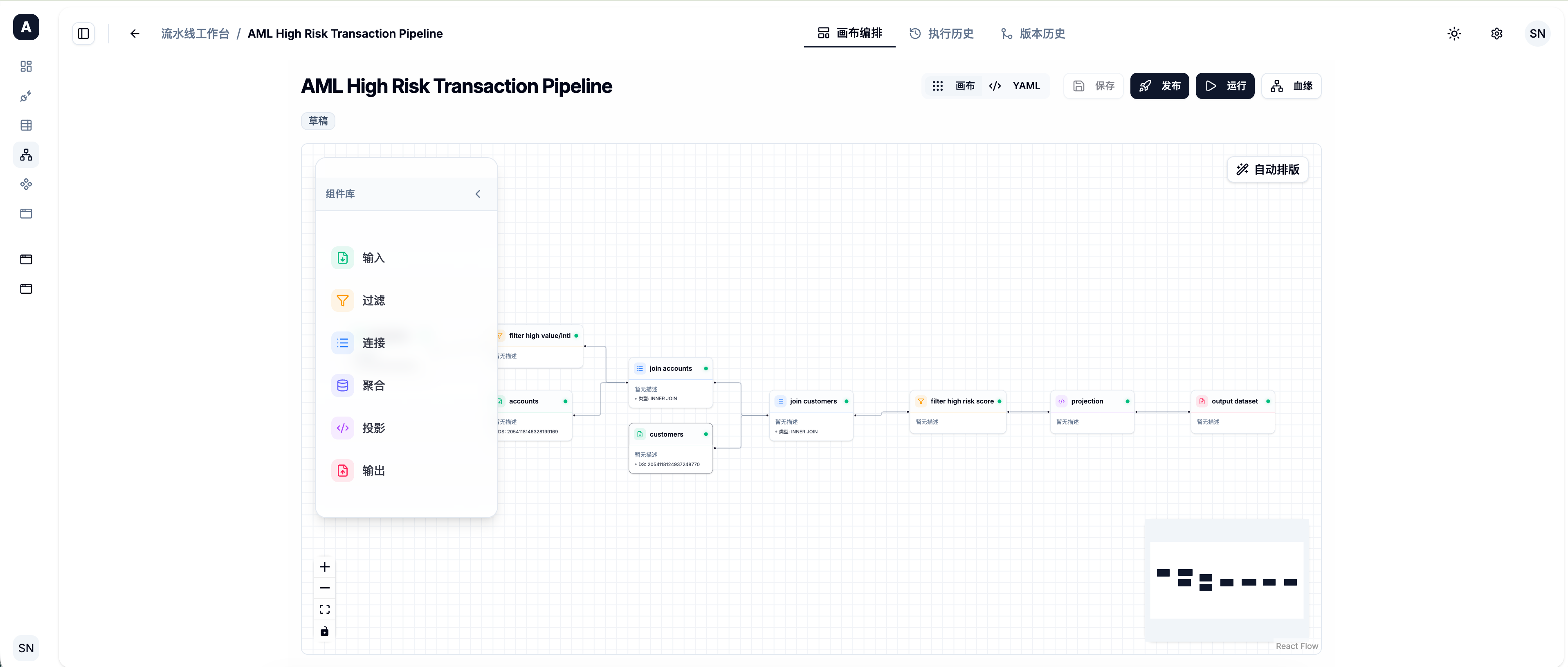
很多时候,原始数据并不能直接给业务用(比如需要关联其他表、需要过滤掉被软删除的数据、或者需要按天聚合销售额)。这时候你就需要使用流水线 (Pipeline)。
Pipeline 采用可视化的 有向无环图 (DAG) 编排方式。
- 在左侧导航栏点击 [流水线],新建一个 Pipeline。
- 进入画布设计器,从左侧组件库拖拽一个刚刚同步的
Raw Dataset作为输入节点。 - 拖拽一个 算子 (Transform) 节点并连线。目前支持的算子包括:
- SQL 算子:直接编写标准 SQL 进行清洗。
- Filter 算子:可视化配置过滤条件。
- Join 算子:配置多表关联逻辑。
- 拖拽一个
Derived Dataset作为输出节点。 - 点击右上角的 [执行],底层计算引擎(Spark/Flink)会开始运行任务,并将清洗后的结果写入数据湖,生成一个新的派生数据集。
2.3 版本与调度
Pipeline 不仅可以手动执行,还可以配置定时调度 (Cron Schedule)。
每次 Pipeline 成功运行,输出的派生数据集版本号就会 +1。这为底层数据湖的 Time Travel 查询和错误回滚提供了基础。